We are observing stealth crawling behavior from Perplexity, an AI-powered answer engine. Although Perplexity initially crawls from their declared user agent, when they are presented with a network block, they appear to obscure their crawling identity in an attempt to circumvent the website‚Äôs preferences. We see continued evidence that Perplexity is repeatedly modifying their user agent and changing their source ASNs to hide their crawling activity, as well as ignoring ‚Ä?or sometimes failing to even fetch ‚Ä?robots.txt files.
The Internet as we have known it for the past three decades is rapidly changing, but one thing remains constant: it is built on trust. There are clear preferences that crawlers should be transparent, serve a clear purpose, perform a specific activity, and, most importantly, follow website directives and preferences. Based on Perplexity’s observed behavior, which is incompatible with those preferences, we have de-listed them as a verified bot and added heuristics to our managed rules that block this stealth crawling.
We received complaints from customers who had both disallowed Perplexity crawling activity in their robots.txt files and also created WAF rules to specifically block both of Perplexity’s declared crawlers: PerplexityBot and Perplexity-User. These customers told us that Perplexity was still able to access their content even when they saw its bots successfully blocked. We confirmed that Perplexity’s crawlers were in fact being blocked on the specific pages in question, and then performed several targeted tests to confirm what exact behavior we could observe.
We created multiple brand-new domains, similar to testexample.com and secretexample.com. These domains were newly purchased and had not yet been indexed by any search engine nor made publicly accessible in any discoverable way. We implemented a robots.txt file with directives to stop any respectful bots from accessing any part of a website:  

We conducted an experiment by querying Perplexity AI with questions about these domains, and discovered Perplexity was still providing detailed information regarding the exact content hosted on each of these restricted domains. This response was unexpected, as we had taken all necessary precautions to prevent this data from being retrievable by their crawlers.


Bypassing Robots.txt and undisclosed IPs/User Agents
Our multiple test domains explicitly prohibited all automated access by specifying in robots.txt and had specific WAF rules that blocked crawling from Perplexity’s public crawlers. We observed that Perplexity uses not only their declared user-agent, but also a generic browser intended to impersonate Google Chrome on macOS when their declared crawler was blocked.
Declared | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Perplexity-User/1.0; +https://perplexity.ai/perplexity-user) | 20-25m daily requests |
Stealth | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 | 3-6m daily requests |
Both their declared and undeclared crawlers were attempting to access the content for scraping contrary to the web crawling norms as outlined in RFC 9309.
This undeclared crawler utilized multiple IPs not listed in Perplexity’s official IP range, and would rotate through these IPs in response to the restrictive robots.txt policy and block from Cloudflare. In addition to rotating IPs, we observed requests coming from different ASNs in attempts to further evade website blocks. This activity was observed across tens of thousands of domains and millions of requests per day. We were able to fingerprint this crawler using a combination of machine learning and network signals.
An example: 

Of note: when the stealth crawler was successfully blocked, we observed that Perplexity uses other data sources ‚Ä?including other websites ‚Ä?to try to create an answer. However, these answers were less specific and lacked details from the original content, reflecting the fact that the block had been successful.¬†
In contrast to the behavior described above, the Internet has expressed clear preferences on how good crawlers should behave. All well-intentioned crawlers acting in good faith should:
Be transparent. Identify themselves honestly, using a unique user-agent, a declared list of IP ranges or Web Bot Auth integration, and provide contact information if something goes wrong.
Be well-behaved netizens. Don’t flood sites with excessive traffic, scrape sensitive data, or use stealth tactics to try and dodge detection.
Serve a clear purpose. Whether it’s powering a voice assistant, checking product prices, or making a website more accessible, every bot has a reason to be there. The purpose should be clearly and precisely defined and easy for site owners to look up publicly.
Separate bots for separate activities. Perform each activity from a unique bot. This makes it easy for site owners to decide which activities they want to allow. Don’t force site owners to make an all-or-nothing decision.
Follow the rules. That means checking for and respecting website signals like robots.txt, staying within rate limits, and never bypassing security protections.
More details are outlined in our official Verified Bots Policy Developer Docs.
OpenAI is an example of a leading AI company that follows these best practices. They clearly outline their crawlers and give detailed explanations for each crawler’s purpose. They respect robots.txt and do not try to evade either a robots.txt directive or a network level block. And ChatGPT Agent is signing http requests using the newly proposed open standard Web Bot Auth.
When we ran the same test as outlined above with ChatGPT, we found that ChatGPT-User fetched the robots file and stopped crawling when it was disallowed. We did not observe follow-up crawls from any other user agents or third party bots. When we removed the disallow directive from the robots entry, but presented ChatGPT with a block page, they again stopped crawling, and we saw no additional crawl attempts from other user agents. Both of these demonstrate the appropriate response to website owner preferences.

All the undeclared crawling activity that we observed from Perplexity’s hidden User Agent was scored by our bot management system as a bot and was unable to pass managed challenges. Any bot management customer who has an existing block rule in place is already protected. Customers who don’t want to block traffic can set up rules to challenge requests, giving real humans an opportunity to proceed. Customers with existing challenge rules are already protected. Lastly, we added signature matches for the stealth crawler into our managed rule that blocks AI crawling activity. This rule is available to all customers, including our free customers.  
It's been just over a month since we announced Content Independence Day, giving content creators and publishers more control over how their content is accessed. Today, over two and a half million websites have chosen to completely disallow AI training through our managed robots.txt feature or our managed rule blocking AI Crawlers. Every Cloudflare customer is now able to selectively decide which declared AI crawlers are able to access their content in accordance with their business objectives.
We expected a change in bot and crawler behavior based on these new features, and we expect that the techniques bot operators use to evade detection will continue to evolve. Once this post is live the behavior we saw will almost certainly change, and the methods we use to stop them will keep evolving as well. 
Cloudflare is actively working with technical and policy experts around the world, like the IETF efforts to standardize extensions to robots.txt, to establish clear and measurable principles that well-meaning bot operators should abide by. We think this is an important next step in this quickly evolving space.

Creators that monetize their content by showing ads depend on traffic volume. Their livelihood is directly linked to the number of views their content receives. These creators have allowed crawlers on their sites for decades, for a simple reason: search crawlers such as Googlebot made their sites more discoverable, and drove more traffic to their content. Google benefitted from delivering better search results to their customers, and the site owners also benefitted through increased views, and therefore increased revenues.
But recently, a new generation of crawlers has appeared: bots that crawl sites to gather data for training AI models. While these crawlers operate in the same technical way as search crawlers, the relationship is no longer symbiotic. AI training crawlers use the data they ingest from content sites to answer questions for their own customers directly, within their own apps. They typically send much less traffic back to the site they crawled. Our Radar team did an analysis of crawls and referrals for sites behind Cloudflare. As HTML pages are arguably the most valuable content for these crawlers, we calculated crawl ratios by dividing the total number of requests from relevant user agents associated with a given search or AI platform where the response was of Content-type: text/html by the total number of requests for HTML content where the Referer: header contained a hostname associated with a given search or AI platform. As of June 2025, we find that Google crawls websites about 14 times for every referral. But for AI companies, the crawl-to-refer ratio is orders of magnitude greater. In June 2025, OpenAI‚Äôs crawl-to-referral ratio was 1,700:1, Anthropic‚Äôs 73,000:1. This clearly breaks the ‚Äúcrawl in exchange for traffic‚Ä?relationship that previously existed between search crawlers and publishers. (Please note that this calculation reflects our best estimate, recognizing that traffic referred by native apps may not always be attributed to a provider due to a lack of a Referer: header, which may affect the ratio.)
And while sites can use robots.txt to tell these bots not to crawl their site, most don’t take this first step. We found that only about 37% of the top 10,000 domains currently have a robots.txt file, showing that robots.txt is underutilized in this age of evolving crawlers.
That’s where Cloudflare comes in. Our mission is to help build a better Internet, and a better Internet is one with a huge thriving ecosystem of independent publishers. So, we’re taking action to keep that ecosystem alive.
Protecting content creators isn’t new for Cloudflare. In July 2024, we gave everyone on the Cloudflare network a simple way to block all AI scrapers with a single click for free. We’ve already seen more than 1 million customers enable this feature, which has given us some interesting data.
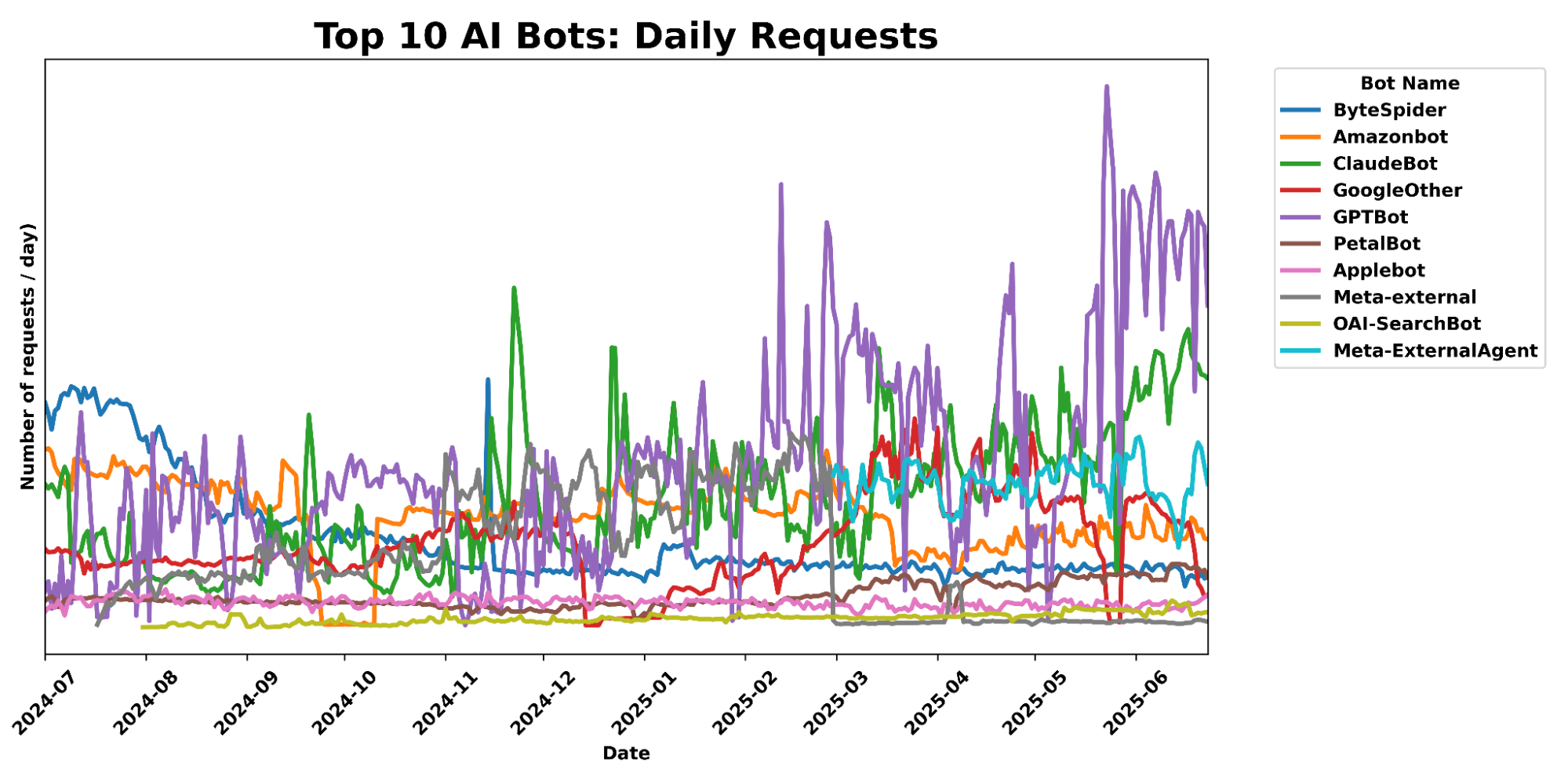
Since our last update, we can see that Bytespider, our previous top bot, has seen traffic volume decline 71.45% since the first week of July 2024. During the same time, we saw an increased number of Bytespider requests that customers chose to specifically block. In contrast, GPTBot traffic volume has grown significantly as it has become more popular, now even surpassing traffic we see from big traditional tech players like Amazon and ByteDance.
The share of sites accessed by particular crawlers has gone down across the board since our last update. Previously, Bytespider accessed >40% of websites protected by Cloudflare, but that number has dropped to only 9.37%. GPTBot has taken the top spot for most sites accessed, but while its request volume has grown significantly (noted above), the share of sites it crawls has actually decreased since last year from 35.46% to 28.97%, with an increase in customers blocking.
AI Bot | Share of Websites Accessed |
GPTBot | 28.97% |
Meta-ExternalAgent | 22.16% |
ClaudeBot | 18.80% |
Amazonbot | 14.56% |
Bytespider | 9.37% |
GoogleOther | 9.31% |
ImageSiftBot | 4.45% |
Applebot | 3.77% |
OAI-SearchBot | 1.66% |
ChatGPT-User | 1.06% |
And while AI Search and AI Assistant crawling related activity has exploded in popularity in the last 6 months, we still see their total traffic pale in comparison to AI training crawl activity, which has seen a 65% increase in traffic over the past 6 months.
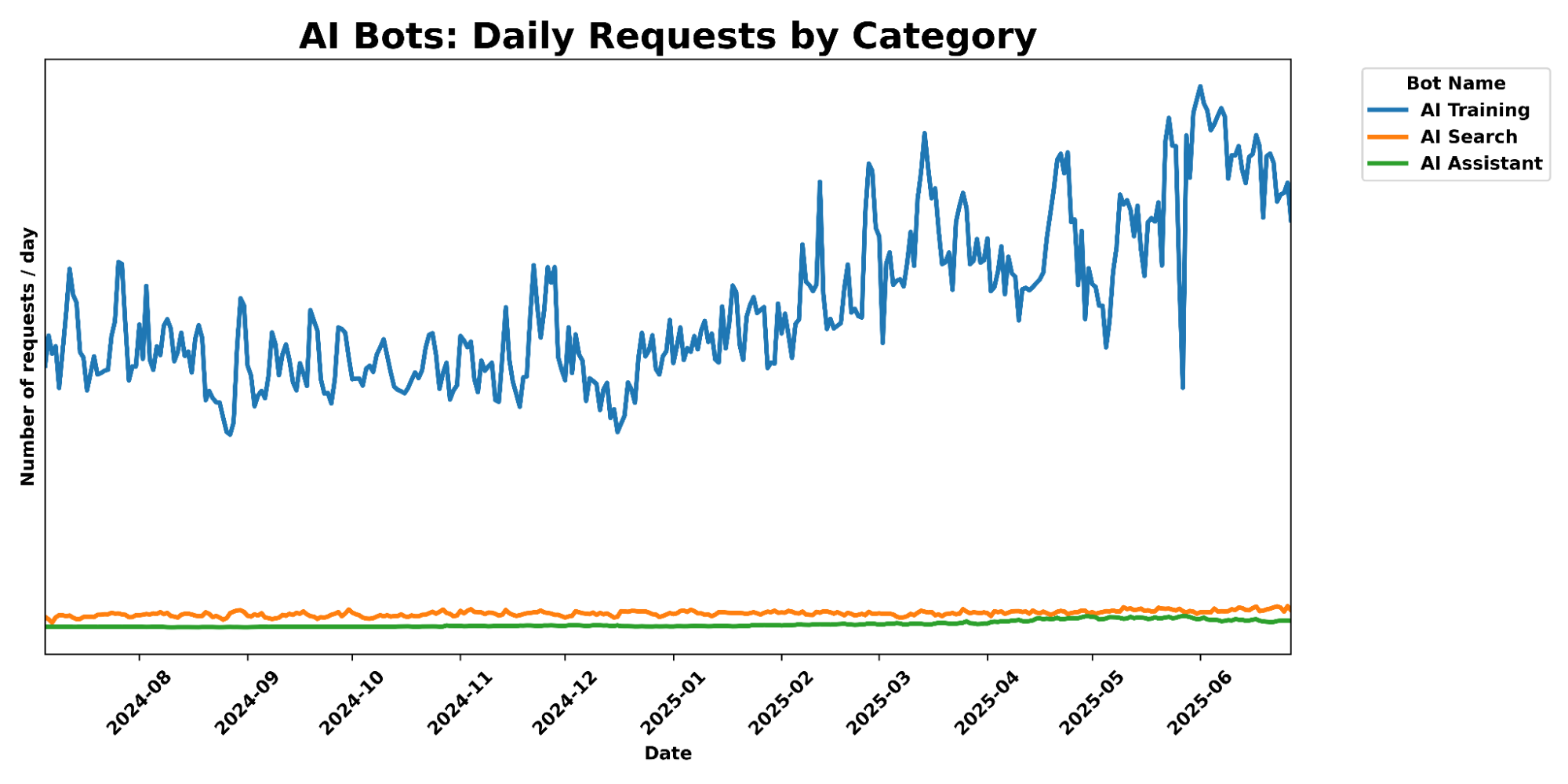
To this end, we launched free granular auditing in September 2024 to help customers understand which crawlers were accessing their content most often, and created simple templates to block all or specific crawlers. And in December 2024, we made it easy for publishers to automatically block crawlers that weren’t respecting robots.txt. But we realized many sites didn’t have the time to create or manage their own robots.txt file. Today, we’re going two steps further.
When it comes to managing your website’s visibility to search engine crawlers and other bots, the robots.txt file is a key player. This simple text file acts like a traffic controller, signaling to bots which parts of the website they should or should not access. We can think of robots.txt as a "Code of Conduct" sign posted at a community pool, listing general dos and don'ts, according to the pool owner’s wishes. While the sign itself does not enforce the listed directives, well-behaved visitors will still read the sign and follow the instructions they see. On the other hand, poorly-behaved visitors who break the rules risk getting themselves banned.
What do these files actually look like? Take Google’s as an example, visible to anyone at https://www.google.com/robots.txt. Parsing its contents, you'll notice four directives in the set of instructions: User-agent, Disallow, Allow, and Sitemap. In a robots.txt file, the User-agent directive specifies which bots the rules apply to. The Disallow directive tells those bots which parts of the website they should avoid. In contrast, the Allow directive grants specific bots permission to access certain areas. Finally, the Sitemap directive shows a bot which pages it can reach, so that it won’t miss any important pages. The Internet Engineering Task Force (IETF) formalized the definition and language for the Robots Exclusion Protocol in RFC 9309, specifying the exact syntax and precedence of these directives. It also outlines how crawlers should handle errors or redirects while stressing that compliance is voluntary and does not constitute access control. 

Website owners should have agency over AI bot activity on their websites. We mentioned that only 37% of the top 10,000 domains on Cloudflare even have a robots.txt file. Of those robots files that do exist, few include Disallow directives for the top AI Bots that we see on a daily basis.  For instance, as of publication, GPTBot is only disallowed in 7.8% of the robots.txt files found for the top domains; Google-Extended only shows up in 5.6%; anthropic-ai, PerplexityBot, ClaudeBot, and Bytespider each show up in under 5%. Furthermore, the difference between the 7.8% of Disallow directives for GPTBot and the ~5% of Disallow directives for other major AI crawlers suggests a gap between the desire to prevent your content from being used for AI model training and the proper configuration that accomplishes this by calling out bots like Google-Extended. (After all, there’s more to stopping AI crawlers than disallowing GPTBot.)
Along with viewing the most active bots and crawlers, Cloudflare Radar also shares weekly updates on how websites are handling AI bots in their robots.txt files. We can examine two snapshots below, one from June 2025 and the other from January 2025:
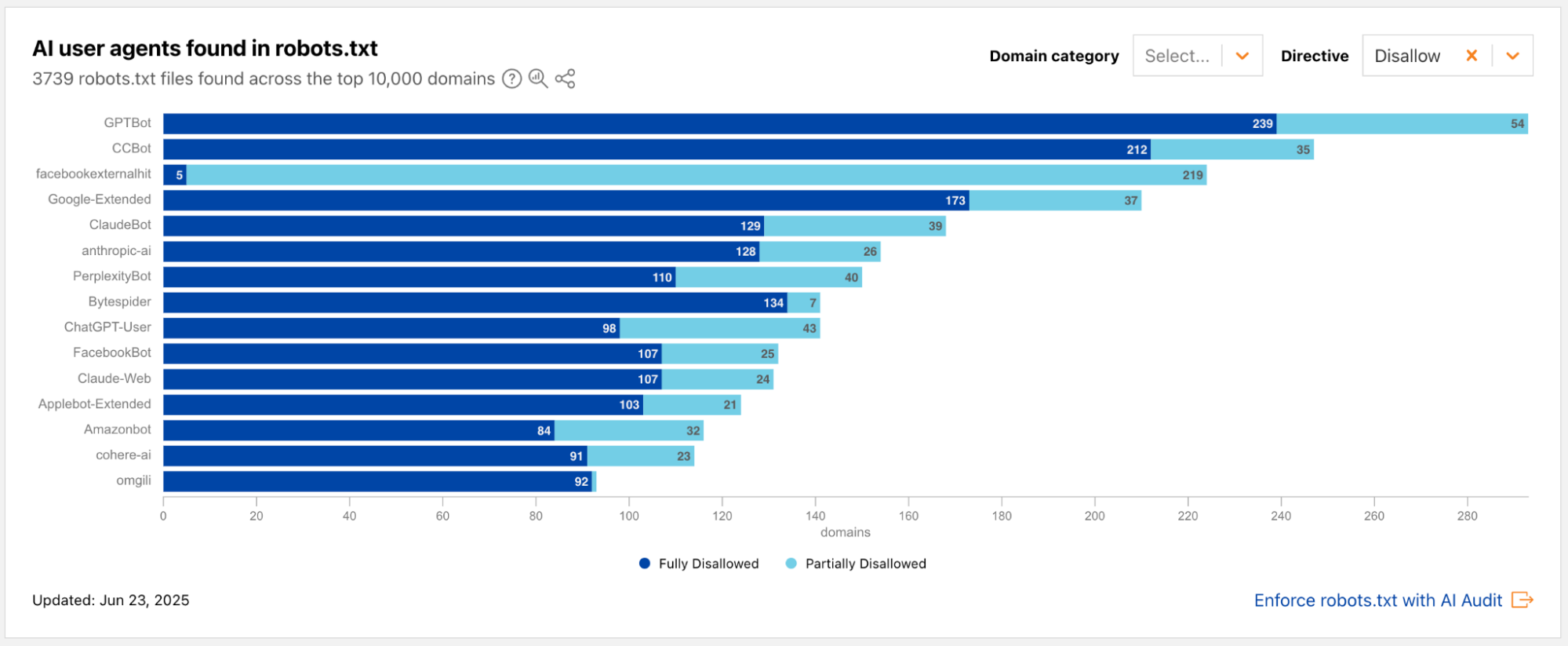
Radar snapshot from the week of June 23, 2025, showing the top AI user agents mentioned in the Disallow directive in robots.txt files across the top 10,000 domains. The 3 bots with the highest number of Disallows are GPTBot, CCBot, and facebookexternalhit.
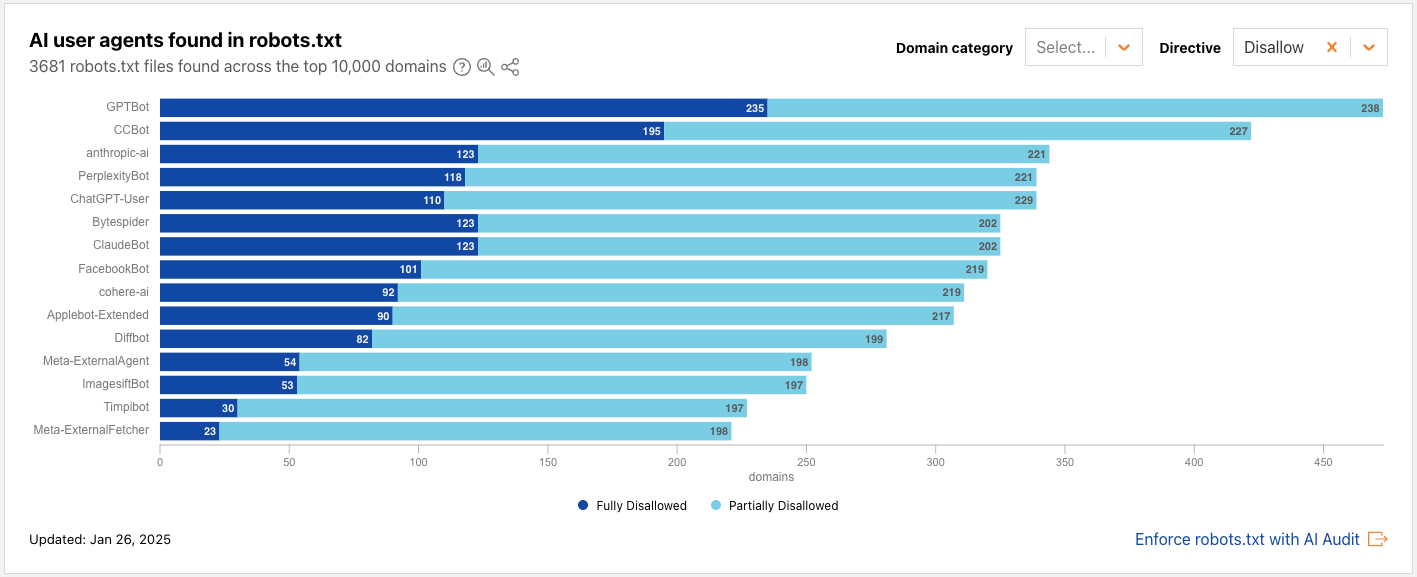
Radar snapshot from the week of January 26, 2025, showing the top AI user agents mentioned in the Disallow directive in robots.txt files across the top 10,000 domains. The 3 bots with the highest number of Disallows are GPTBot, CCBot, and anthropic-ai.
From the above data, we also observe that fewer than 100 new robots.txt files have been added among the top domains between January and June. One visually striking change is the ratio of dark blue to light blue: compared to January, there is a steep decrease in ‚ÄúPartially Disallowed‚Ä?permissions; websites are now flat-out choosing ‚ÄúFully Disallowed‚Ä?for the top AI crawlers, including GPTBot, CCBot, and Google-Extended. This underscores the changing landscape of web crawling, particularly the relationship of trust between website owners and AI crawlers.
Many website owners have told us they’re in a tricky spot in this new era of AI crawlers. They’ve poured time and effort into creating original content, have published it on their own sites, and naturally want it to reach as many people as possible. To do that, website owners make their sites accessible to search engine crawlers, which index the content and make it discoverable in search results. But with the rise of AI-powered crawlers, that same content is now being scraped not just for indexing, but also to train AI models, often without the creator’s explicit consent. Take Googlebot, for example: it’s an absolute requirement for most website owners to allow for SEO. But Google crawls with user agent Googlebot for both SEO and AI training purposes. Specifically disallowing Google-Extended (but not Googlebot) in your robots.txt file is what communicates to Google that you do not want your content to be crawled to feed AI training.
So, what if you don’t want your content to serve as training data for the next AI model, but don’t have the time to manually maintain an up-to-date robots.txt file? Enter Cloudflare’s new managed robots.txt offering. Once enabled, Cloudflare will automatically update your existing robots.txt or create a robots.txt file on your site that includes directives asking popular AI bot operators to not use your content for AI model training. For instance, Cloudflare’s managed robots.txt signals your preference to Google-Extended and Applebot-Extended, amongst others, that they should not crawl your site for AI training, while keeping your domain(s) SEO-friendly.
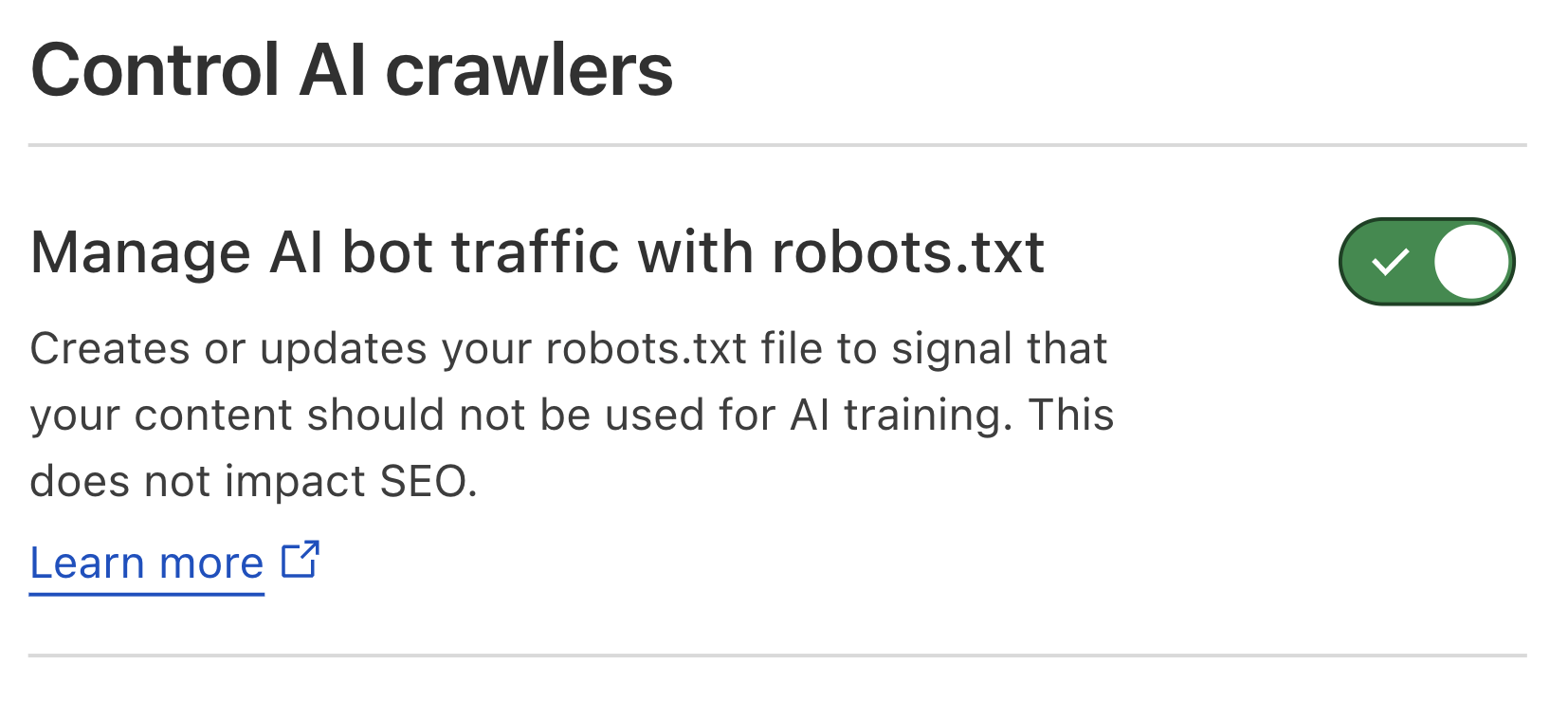
Cloudflare dashboard snapshot of the new managed robots.txt activation toggle 
This feature is available to all customers, meaning anyone can enable this today from the Cloudflare dashboard. Once enabled, website owners who previously had no robots.txt file will now have Cloudflare‚Äôs managed bot directives live on their website. What about website owners who already have a robots.txt file? The contents of Cloudflare‚Äôs managed robots.txt will be prepended to site owners‚Ä?existing file. This way, their existing Block directives ‚Ä?and the time and rationale put into customizing this file ‚Ä?are honored, while still ensuring the website has AI crawler guardrails managed by Cloudflare.
As the AI bot landscape changes with new bots on the rise, Cloudflare will keep our customers a step ahead by updating the directives on our managed robots.txt, so they don’t have to worry about maintaining things on their own. Once enabled, customers won’t need to take any action in order for any updates of the managed robots.txt content to go live on their site. 
We believe that managing crawling is key to protecting the open Internet, so we’ll also be encouraging every new site that onboards to Cloudflare to enable our managed robots.txt. When you onboard a new site, you’ll see the following options for managing AI crawlers:

This makes it effortless to ensure that every new customer or domain onboarded to Cloudflare gives clear directives to how they want their content used.
To implement this feature, we developed a new module that intercepts all inbound HTTP requests for /robots.txt. For all such requests, we’ll check whether the zone has opted in to use Cloudflare’s managed robots.txt by reading a value from our distributed key-value store. If they have, the module then responds with the Cloudflare’s managed robots.txt directives, prepended to the origin’s robot.txt if there is an existing file. We prepend so we can add a generalized header that instructs all bots on the customers preferences for data use, as defined in the IETF AI preferences proposal. Note that in robots.txt, the most specific match must always be used, and since our disallow expressions are scoped to cover everything, we can ensure a directive we prepend will never conflict with a more targeted customer directive. If the customer has not enabled this feature, the request is forwarded to the origin server as usual, using whatever the customer has written in their own robots.txt file. (While caching origin's robots.txt could reduce latency by eliminating a round trip to the origin, the impact on overall page load times would be minimal, as robots.txt requests comprise a small fraction of total traffic. Adding cache update/invalidation would introduce complexity with limited benefit, so we prioritized functionality and reliability in our implementation.)
Adding an entry to your robots.txt file is the first step to telling AI bots not to crawl you. But robots.txt is an honor system. Nothing forces bots to follow it. That’s why we introduced our one-click managed rule to block all AI bots across your zone. However, some customers want AI bots to visit certain pages, like developer or support documentation. For customers who are hesitant to block everywhere, we have a brand-new option: let us detect when ads are shown on a hostname, and we will block AI bots ONLY on that hostname. Here’s how we do it.
First, we use multiple techniques to identify if a request is coming from an AI bot. The easiest technique is to identify well-behaved crawlers that publicly declare their user agent, and use dedicated IP ranges. Often we work directly with these bot makers to add them to our Verified Bot list.
Many bot operators act in good faith by publicly publishing their user agents, or even cryptographically verifying their bot requests directly with Cloudflare. Unfortunately, some attempt to appear like a real browser by using a spoofed user agent. It's not new for our global machine learning models to recognize this activity as a bot, even when operators lie about their user agent. When bad actors attempt to crawl websites at scale, they generally use tools and frameworks that we’re able to fingerprint, and we use Cloudflare’s network of over 57 million requests per second on average, to understand how much we should trust the fingerprint. We compute global aggregates across many signals, and based on these signals, our models are able to consistently and appropriately flag traffic from evasive AI bots.
When we see a request from an AI bot, our system checks if we have previously identified ads in the response served by the target page. To do this, we inspect the ‚Äúresponse body‚Ä?‚Ä?the raw HTML code of the web page being sent back.¬† After parsing the HTML document, we perform a comprehensive scan for code patterns commonly found in ad units, which signals to us that the page is serving an ad. Examples of such code would be:
<div class="ui-advert" data-role="advert-unit" data-testid="advert-unit" data-ad-format="takeover" data-type="" data-label="" style="">
<script>
....
</script>
</div>Here, the div-container has the ui-advert class commonly used for advertising. Similarly, links to commonly used ad servers like Google Syndication are a good signal as well, such as the following:
<link rel="dns-prefetch" href="https://pagead2.googlesyndication.com/">
<script async src="https://pagead2.googlesyndication.com/pagead/js/adsbygoogle.js?client=ca-pub-1234567890123456" crossorigin="anonymous"></script>By streaming and directly parsing small chunks of the response using our ultra-fast LOL HTML parser, we can perform scans without adding any latency to the inspected response.
So as not to reinvent the wheel, we are adopting techniques similar to those that ad blockers have been using for years. Ad blockers fundamentally perform two separate tasks to block advertisements in a browser. The first is to block the browser from fetching resources from ad servers, and the second is to suppress displaying HTML elements that contain ads. For this, ad blockers rely on large filter lists such as EasyList that contain both so-called URL block filters that match outgoing request URLs against a set of patterns, and block them if they match one of the filters, and CSS selectors that are designed to match HTML ad elements.
We can use both of these techniques to detect if an HTML response contains ads by checking external resources (e.g. content referenced by HREF or SCRIPT tags) against URL block filters, and the HTML elements themselves against CSS selectors. Because we do not actually need to block every single advertisement on a site, but rather detect the overall presence of ads on a site, we can achieve the same detection efficacy when shrinking the number of CSS and URL filters down from more than 40,000 in EasyList to the 400 most commonly seen ones to increase our computational efficiency.
Because some sites load ads dynamically rather than directly in the returned HTML (partially to avoid ad blocking), we enrich this first information source with data from Content Security Policy (CSP) reports. The Content Security Policy standard is a security mechanism that helps web developers control the resources (like scripts, stylesheets, and images) a browser is allowed to load for a specific web page, and browsers send reports about loaded resources to a CSP management system, which for many sites is Cloudflare’s Page Shield product. These reports allow us to relate scripts loaded from ad servers directly with page URLs. Both of these information sources are consumed by our endpoint management service, which then matches incoming requests against hostnames that we already know are serving ads.
We do all of this on every request for any customer who opts in, even free customers. 
To enable this feature, simply navigate to the Security > Settings > Bots section of the Cloudflare dashboard, and choose either Block on pages with Ads or Block Everywhere.
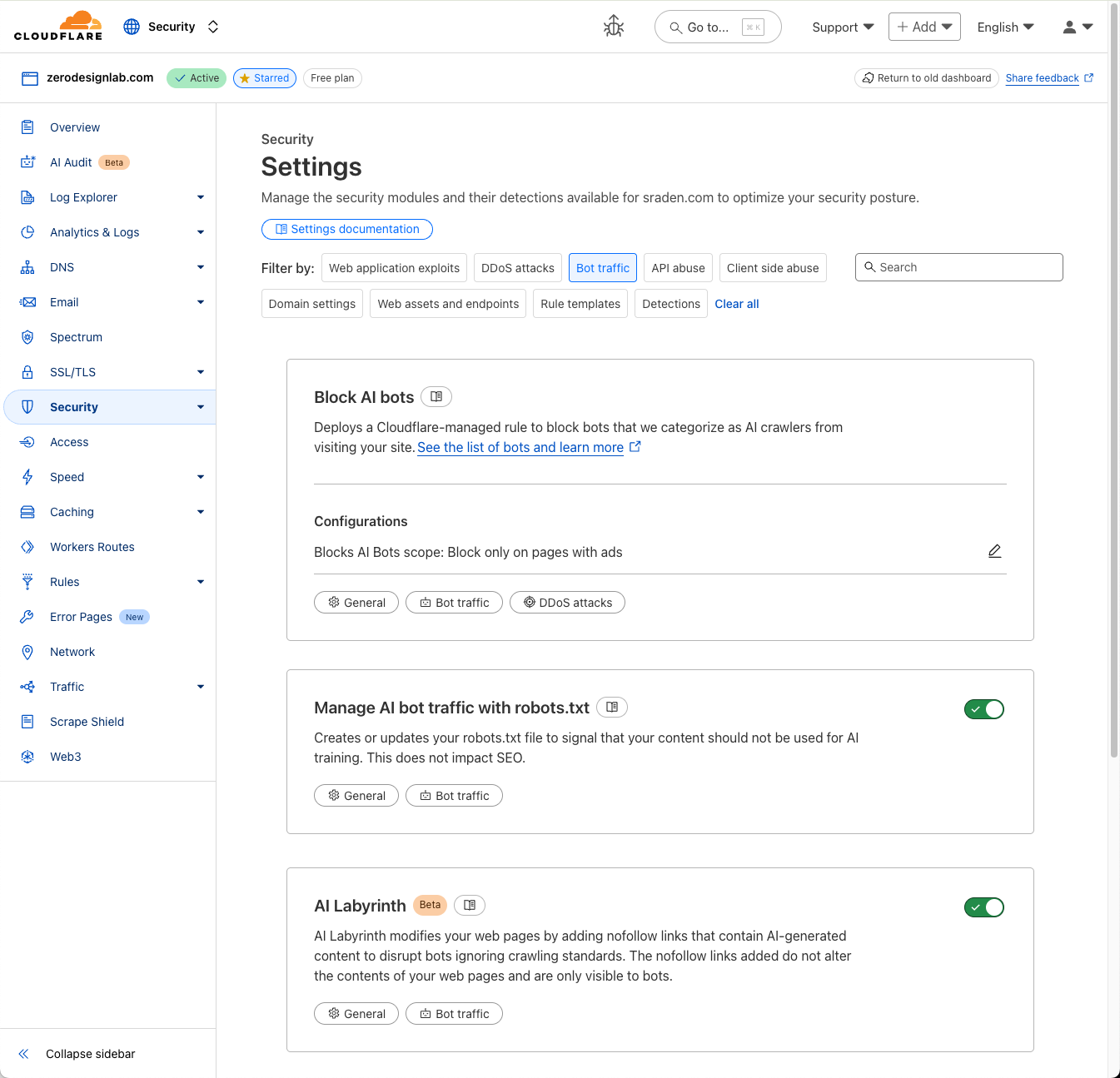
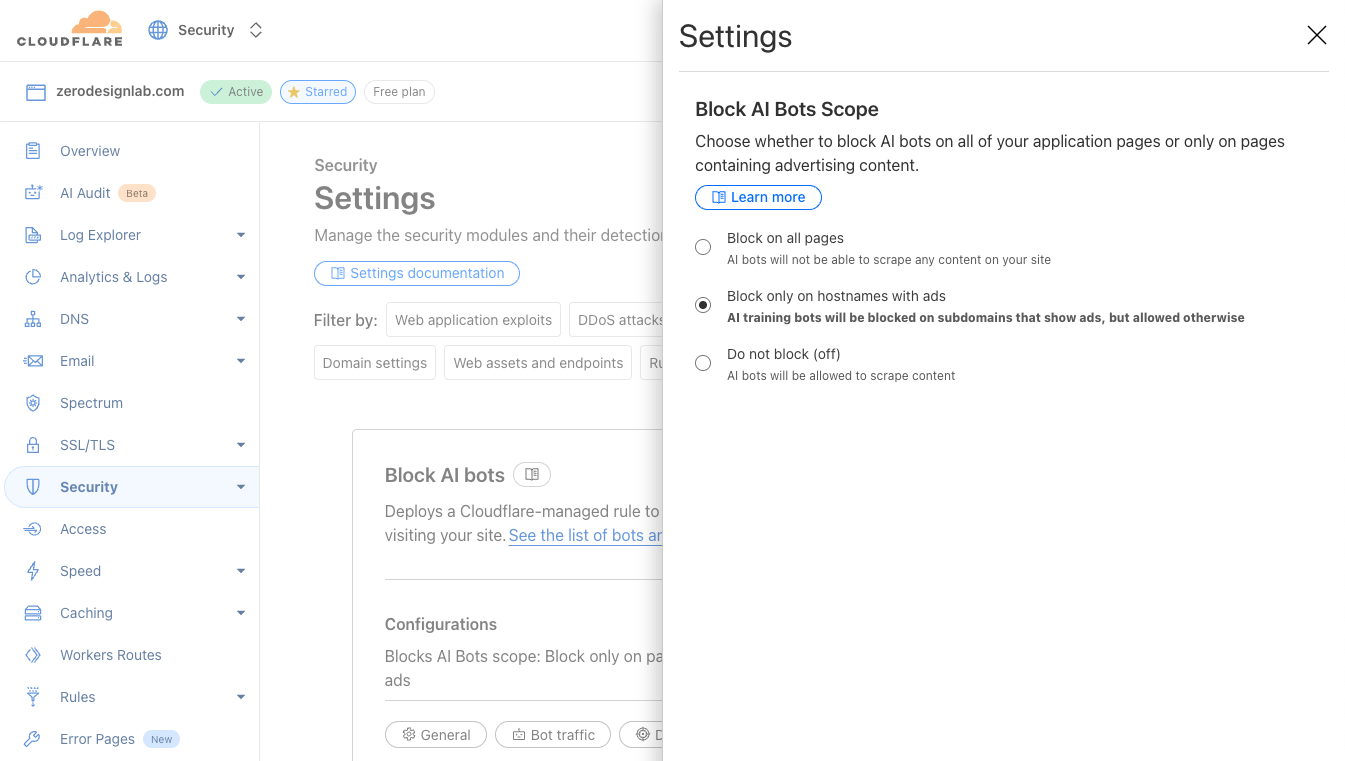
The AI bot landscape has exploded and continues to grow with an exponential trajectory as more and more operators come online. At Cloudflare, our team of security researchers are constantly identifying and classifying different AI-related crawlers and scrapers across our network. 
There are two major ways in which we track AI bots and identify those that are poorly behaved:
1. Our customers play a crucial role by directly submitting reports of misbehaved AI bots that may not yet be classified by Cloudflare. (If you have an AI bot that comes to mind here, we’d love for you to let us know through our bots submission form today.) Once such a bot comes to our attention, our security analysts investigate to determine how it should be categorized.
2. We‚Äôre able to derive insights through analysis of the massive scale of our customers‚Ä?traffic that we observe. Specifically, we can see which AI agents visit which websites and when, drawing out trends or patterns that might make a website owner want to disallow a given AI bot. This bird‚Äôs-eye view on abusive AI bot behavior was paramount as we started to determine the content of a managed robots.txt.
Our new managed robots.txt and blocking AI bots on pages with ads features are available to all Cloudflare customers, including everyone on a Free plan. We encourage customers to start using them today ‚Ä?to take control over how the content on your website gets used. Looking ahead, Cloudflare will monitor the IETF‚Äôs pending proposal allowing website publishers to control how automated systems use their content and update our managed robots.txt accordingly. We will also continue to provide more granular control around AI bot management and investigate new distinguishing signals as AI bots become more and more precise. And if you‚Äôve seen suspicious behavior from an AI scraper, contribute to the Internet ecosystem by letting us know!
]]>In Cloudflare’s bot detection, we build heuristics from attributes like software library fingerprints, HTTP request characteristics, and internal threat intelligence. Heuristics serve three separate purposes for bot detection: 
Bot identification: If traffic matches a heuristic, we can identify the traffic as definitely automated traffic (with a bot score of 1) without the need of a machine learning model. 
Train ML models: When traffic matches our heuristics, we create labelled datasets of bot traffic to train new models. We’ll use many different sources of labelled bot traffic to train a new model, but our heuristics datasets are one of the highest confidence datasets available to us.   
Validate models: We benchmark any new model candidate’s performance against our heuristic detections (among many other checks) to make sure it meets a required level of accuracy.
While the existing heuristics engine has worked very well for us, as bots evolved we needed the flexibility to write increasingly complex rules. Unfortunately, such rules were not easily supported in the old engine. Customers have also been asking for more details about which specific heuristic caught a request, and for the flexibility to enforce different policies per heuristic ID.  We found that by building a new heuristics framework integrated into the Cloudflare Ruleset Engine, we could build a more flexible system to write rules and give Bot Management customers the granular explainability and control they were asking for. 
In our previous heuristics engine, we wrote rules in Lua as part of our openresty-based reverse proxy. The Lua-based engine was limited to a very small number of characteristics in a rule because of the high engineering cost we observed with adding more complexity.
With Lua, we would write fairly simple logic to match on specific characteristics of a request (i.e. user agent). Creating new heuristics of an existing class was fairly straight forward. All we‚Äôd need to do is define another instance of the existing class in our database. However, if we observed malicious traffic that required more than two characteristics (as a simple example, user-agent and ASN) to identify, we‚Äôd need to create bespoke logic for detections. Because our Lua heuristics engine was bundled with the code that ran ML models and other important logic, all changes had to go through the same review and release process. If we identified malicious traffic that needed a new heuristic class, and we were also blocked by pending changes in the codebase, we‚Äôd be forced to either wait or rollback the changes. If we‚Äôre writing a new rule for an ‚Äúunder attack‚Ä?scenario, every extra minute it takes to deploy a new rule can mean an unacceptable impact to our customer‚Äôs business.¬†
More critical than time to deploy is the complexity that the heuristics engine supports. The old heuristics engine only supported using specific request attributes when creating a new rule. As bots became more sophisticated, we found we had to reject an increasing number of new heuristic candidates because we weren’t able to write precise enough rules. For example, we found a Golang TLS fingerprint frequently used by bots and by a small number of corporate VPNs. We couldn’t block the bots without also stopping the legitimate VPN usage as well, because the old heuristics platform lacked the flexibility to quickly compile sufficiently nuanced rules. Luckily, we already had the perfect solution with Cloudflare Ruleset Engine. 
The Ruleset Engine is familiar to anyone who has written a WAF rule, Load Balancing rule, or Transform rule, just to name a few. For Bot Management, the Wireshark-inspired syntax allows us to quickly write heuristics with much greater flexibility to vastly improve accuracy. We can write a rule in YAML that includes arbitrary sub-conditions and inherit the same framework the WAF team uses to both ensure any new rule undergoes a rigorous testing process with the ability to rapidly release new rules to stop attacks in real-time. 
Writing heuristics on the Cloudflare Ruleset Engine allows our engineers and analysts to write new rules in an easy to understand YAML syntax. This is critical to supporting a rapid response in under attack scenarios, especially as we support greater rule complexity. Here’s a simple rule using the new engine, to detect empty user-agents restricted to a specific JA4 fingerprint (right), compared to the empty user-agent detection in the old Lua based system (left): 
Old | New |
|
|
The Golang heuristic that captured corporate proxy traffic as well (mentioned above) was one of the first to migrate to the new Ruleset engine. Before the migration, traffic matching on this heuristic had a false positive rate of 0.01%. While that sounds like a very small number, this means for every million bots we block, 100 real users saw a Cloudflare challenge page unnecessarily. At Cloudflare scale, even small issues can have real, negative impact.
When we analyzed the traffic caught by this heuristic rule in depth, we saw the vast majority of attack traffic came from a small number of abusive networks. After narrowing the definition of the heuristic to flag the Golang fingerprint only when it’s sourced by the abusive networks, the rule now has a false positive rate of 0.0001% (One out of 1 million).  Updating the heuristic to include the network context improved our accuracy, while still blocking millions of bots every week and giving us plenty of training data for our bot detection models. Because this heuristic is now more accurate, newer ML models make more accurate decisions on what’s a bot and what isn’t.
While the new heuristics engine provides more accurate detections for all customers and a better experience for our analysts, moving to the Cloudflare Ruleset Engine also allows us to deliver new functionality for Enterprise Bot Management customers, specifically by offering more visibility. This new visibility is via a new field for Bot Management customers called Bot Detection IDs. Every heuristic we use includes a unique Bot Detection ID. These are visible to Bot Management customers in analytics, logs, and firewall events, and they can be used in the firewall to write precise rules for individual bots. 
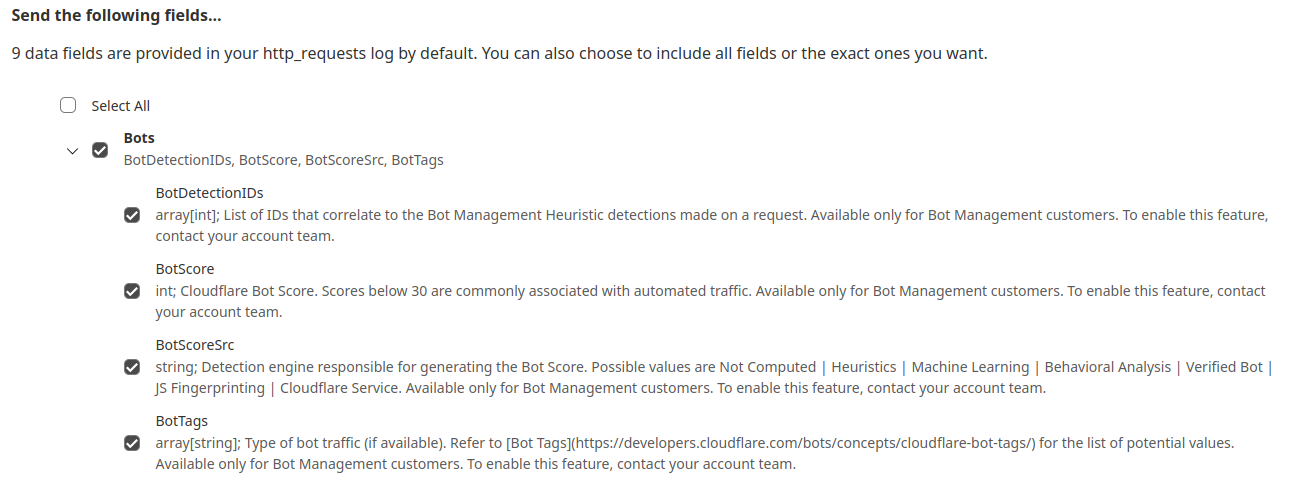
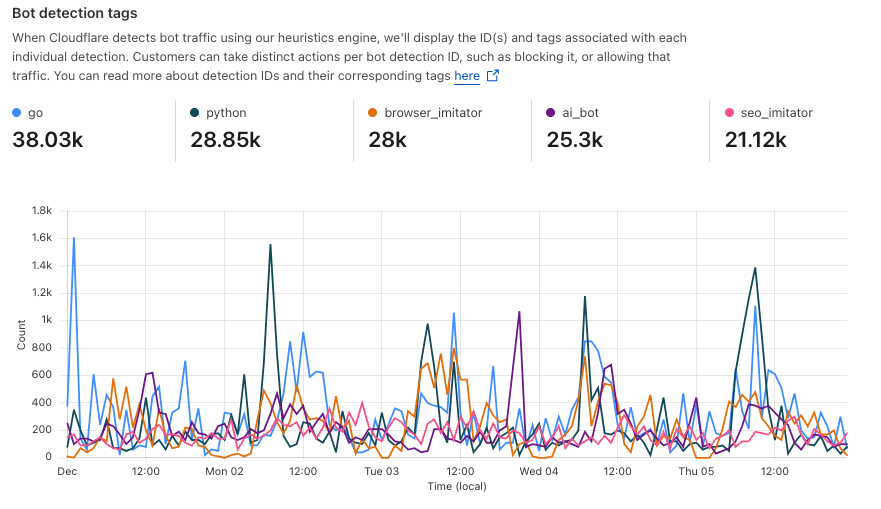
Detections also include a specific tag describing the class of heuristic. Customers see these plotted over time in their analytics.
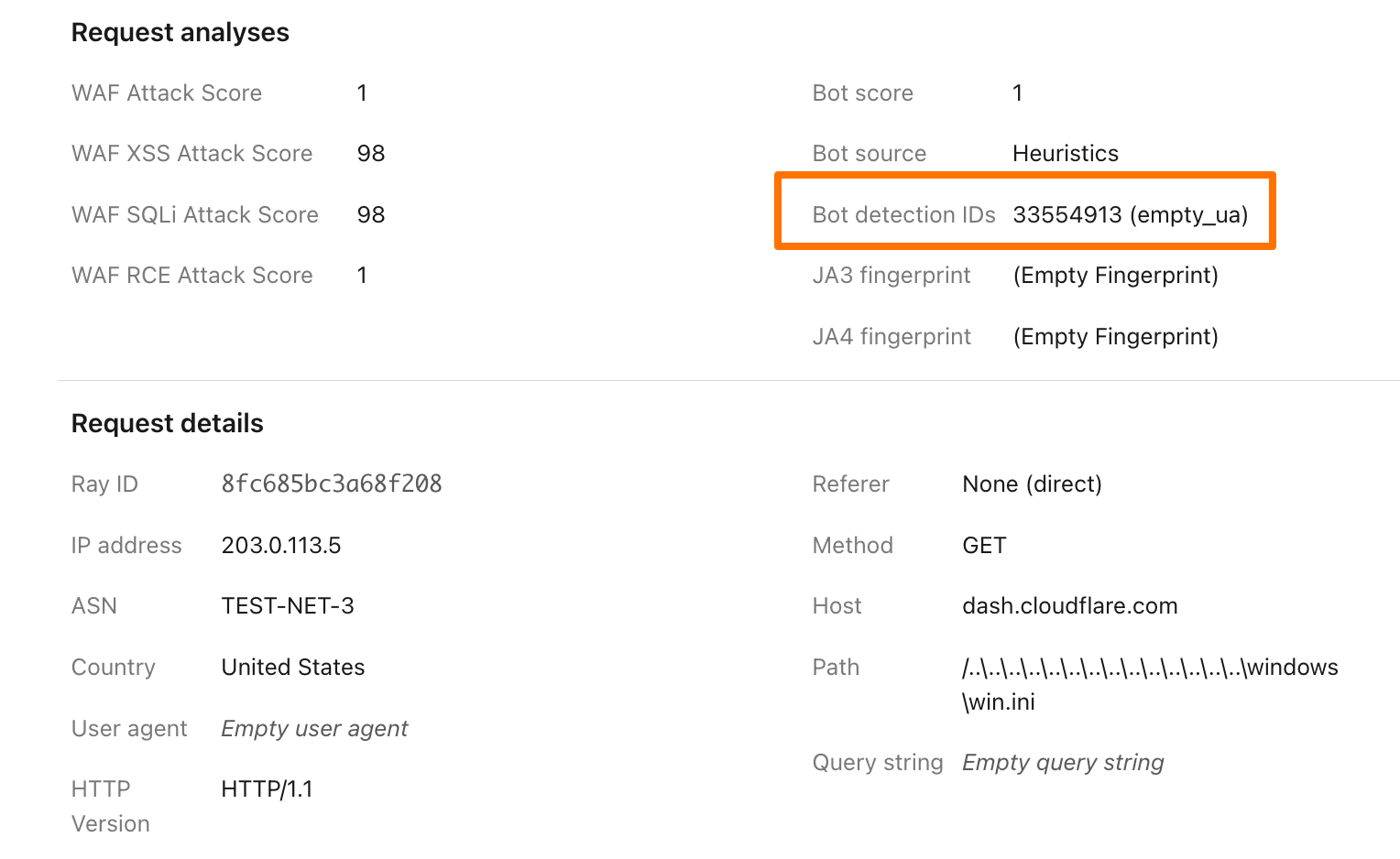
To illustrate how this data can help give customers visibility into why we blocked a request, here’s an example request flagged by Bot Management (with the IP address, ASN, and country changed):

Before, just seeing that our heuristics gave the request a score of 1 was not very helpful in understanding why it was flagged as a bot. Adding our Detection IDs to Firewall Events helps to paint a better picture for customers that we’ve identified this request as a bot because that traffic used an empty user-agent.
In addition to Analytics and Firewall Events, Bot Detection IDs are now available for Bot Management customers to use in Custom Rules, Rate Limiting Rules, Transform Rules, and Workers. 
One way we’re focused on improving Bot Management for our customers is by surfacing more attack-specific detections. During Birthday Week, we launched Leaked Credentials Check for all customers so that security teams could help prevent account takeover (ATO) attacks by identifying accounts at risk due to leaked credentials. We’ve now added two more detections that can help Bot Management enterprise customers identify suspicious login activity via specific detection IDs that monitor login attempts and failures on the zone. These detection IDs are not currently affecting the bot score, but will begin to later in 2025. Already, they can help many customers detect more account takeover events now.
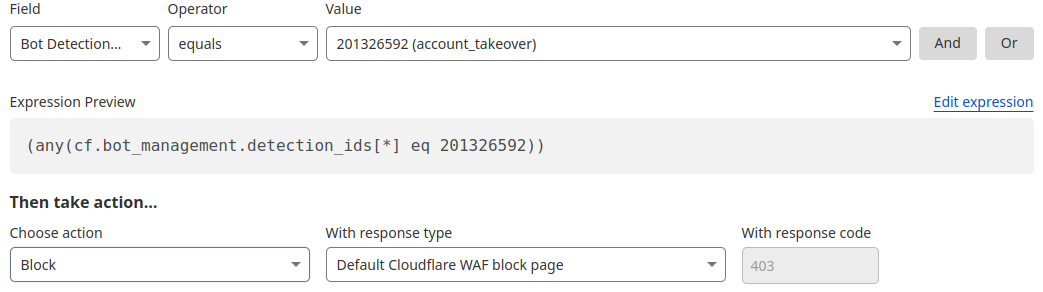
Detection ID 201326592 monitors traffic on a customer website and looks for an anomalous rise in login failures (usually associated with brute force attacks), and ID 201326593 looks for an anomalous rise in login attempts (usually associated with credential stuffing). 
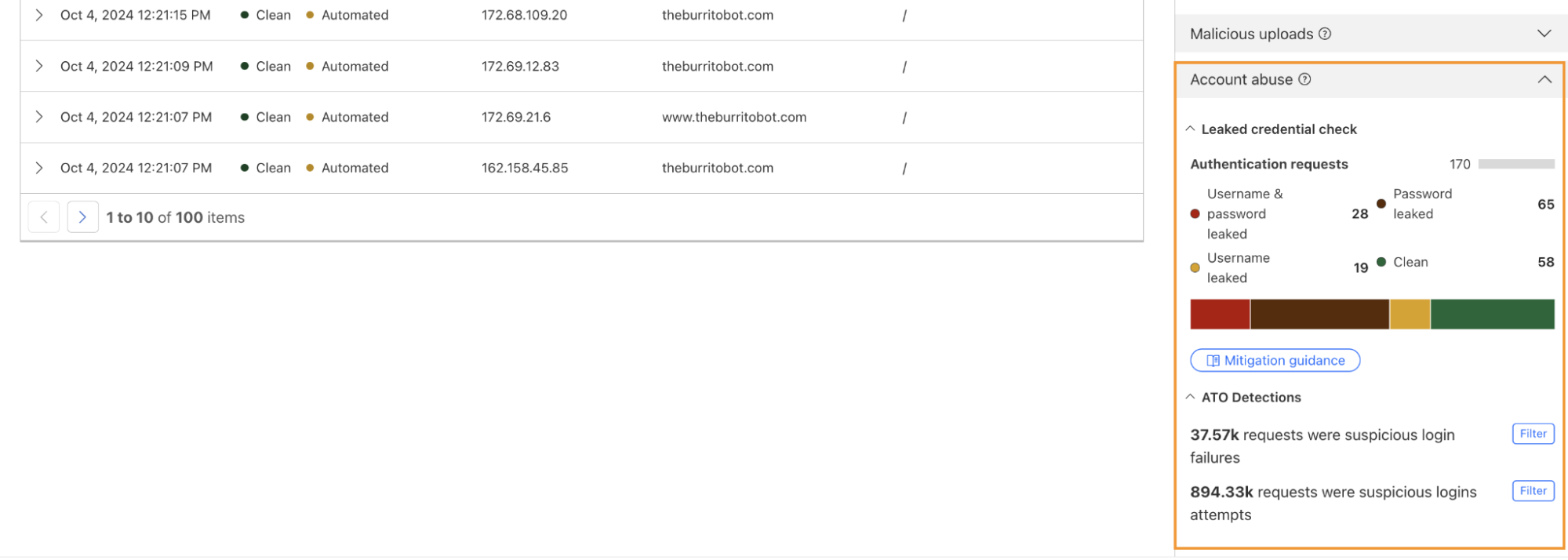
If you are a Bot Management customer, log in and head over to the Cloudflare dashboard and take a look in Security Analytics for bot detection IDs 201326592 and 201326593.
These will highlight ATO attempts targeting your site. If you spot anything suspicious, or would like to be protected against future attacks, create a rule that uses these detections to keep your application safe.
]]>Grinch Bots are still stealing Christmas
Back in 2021, we covered the antics of Grinch Bots and how the combination of proposed regulation and technology could prevent these malicious programs from stealing holiday cheer.
Fast-forward to 2024 ‚Ä?the Stop Grinch Bots Act of 2021 has not passed, and bots are more active and powerful than ever, leaving businesses to fend off increasingly sophisticated attacks on their own. During Black Friday 2024, Cloudflare observed:
29% of all traffic on Black Friday was Grinch Bots. Humans still accounted for the majority of all traffic, but bot traffic was up 4x from three years ago in absolute terms. 
1% of traffic on Black Friday came from AI bots. The majority of it came from Claude, Meta, and Amazon. 71% of this traffic was given the green light to access the content requested. 
63% of login attempts across our network on Black Friday were from bots. While this number is high, it was down a few percentage points compared to a month prior, indicating that more humans accessed their accounts and holiday deals. 
Human logins on e-commerce sites increased 7-8% compared to the previous month. 
These days, holiday shopping doesn’t start on Black Friday and stop on Cyber Monday. Instead, it stretches through Cyber Week and beyond, including flash sales, pre-orders, and various other promotions. While this provides consumers more opportunities to shop, it also creates more openings for Grinch Bots to wreak havoc.
Black Friday and Cyber Monday in 2024 brought record-breaking shopping ‚Ä?and grinching. In addition to looking across our entire network, we also analyzed traffic patterns specifically on a cohort of e-commerce sites.¬†
Legitimate shoppers flocked to e-commerce sites, with requests reaching an astounding 405 billion on Black Friday, accounting for 81% of the day’s total traffic to e-commerce sites. Retailers reaped the rewards of their deals and advertising, seeing a 50% surge in shoppers week-over-week and a 61% increase compared to the previous month.
Unfortunately, Grinch Bots were equally active. Total e-commerce bot activity surged to 103 billion requests, representing up to 19% of all traffic to e-commerce sites. Nearly one in every five requests to an online store was not a real customer. That’s a lot of resources to waste on bogus traffic. Cyber Week was a battleground, with bots hoarding inventory, exploiting deals, and disrupting genuine shopping experiences.
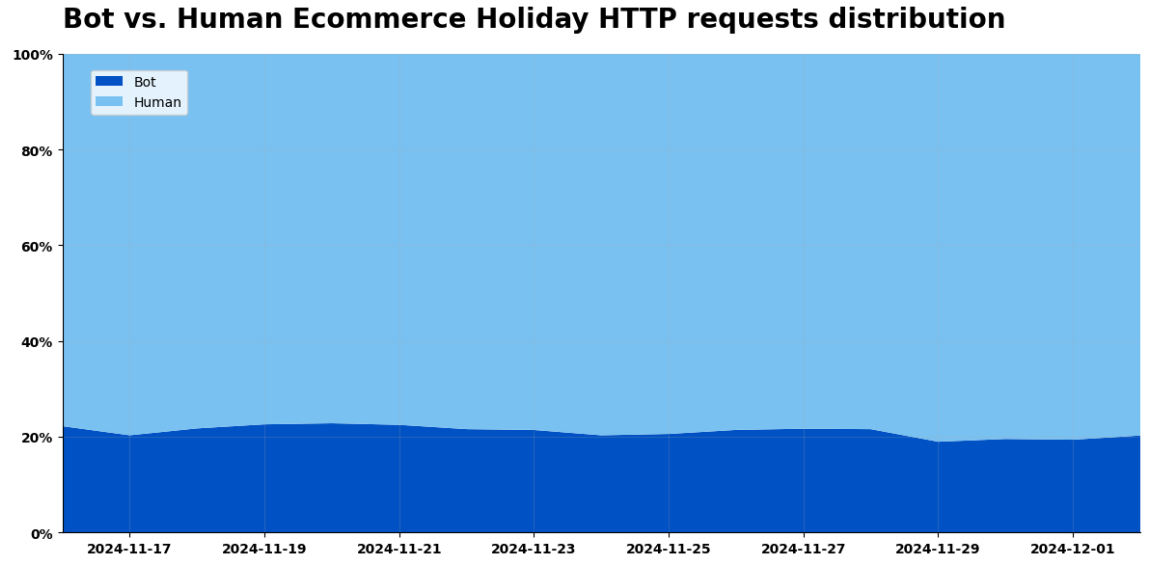
The upside, if there is one, is that there was more human activity on e-commerce sites (81%) than observed on our network more broadly (71%). 
Cloudflare saw 4x more bot requests than what we observed in 2021. Being able to observe and score all this traffic at scale means we can help customers keep the grinches away. We also got to see patterns that help us better identify the concentration of these attacks: 
19% of traffic on e-commerce sites was Grinch Bots
1% of traffic to e-commerce sites was from AI Bots. 
63% of login attempt requests across our network were from bots 
22% of bot activity originated from residential proxy networks

What are all of these bots up to? 
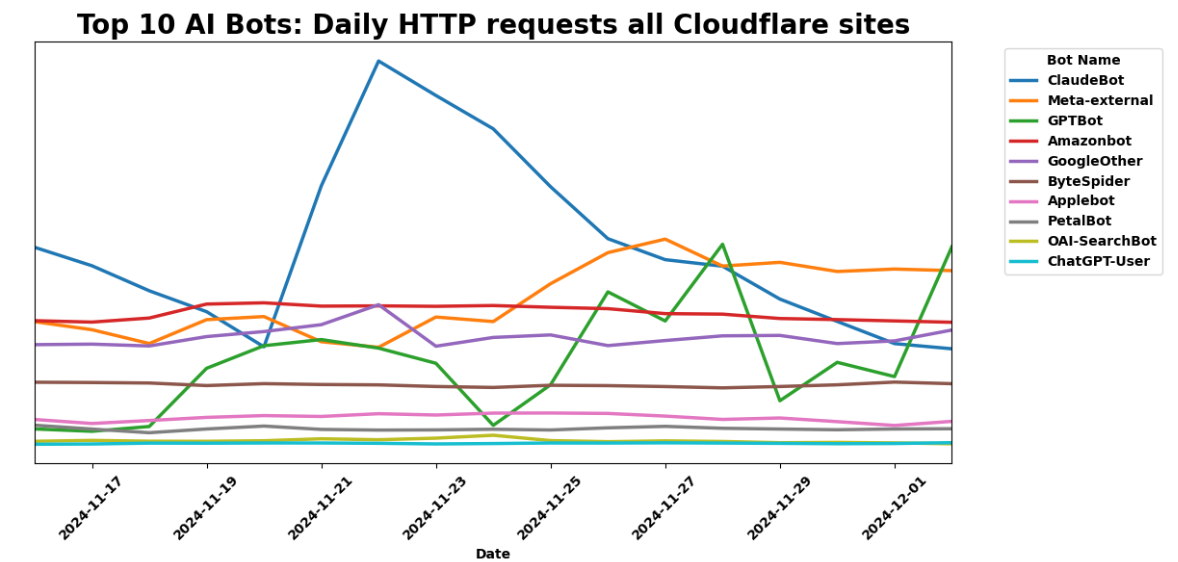
This year marked a breakthrough for AI-driven bots, agents, and models, with their impact spilling into Black Friday. AI bots went from zero to one, now making up 1% of all bot traffic on e-commerce sites. 
AI-driven bots generated 29 billion requests on Black Friday alone, with Meta-external, Claudebot, and Amazonbot leading the pack. Based on their owners, these bots are meant to crawl to augment training data sets for Llama, Claude, and Alexa respectively. 
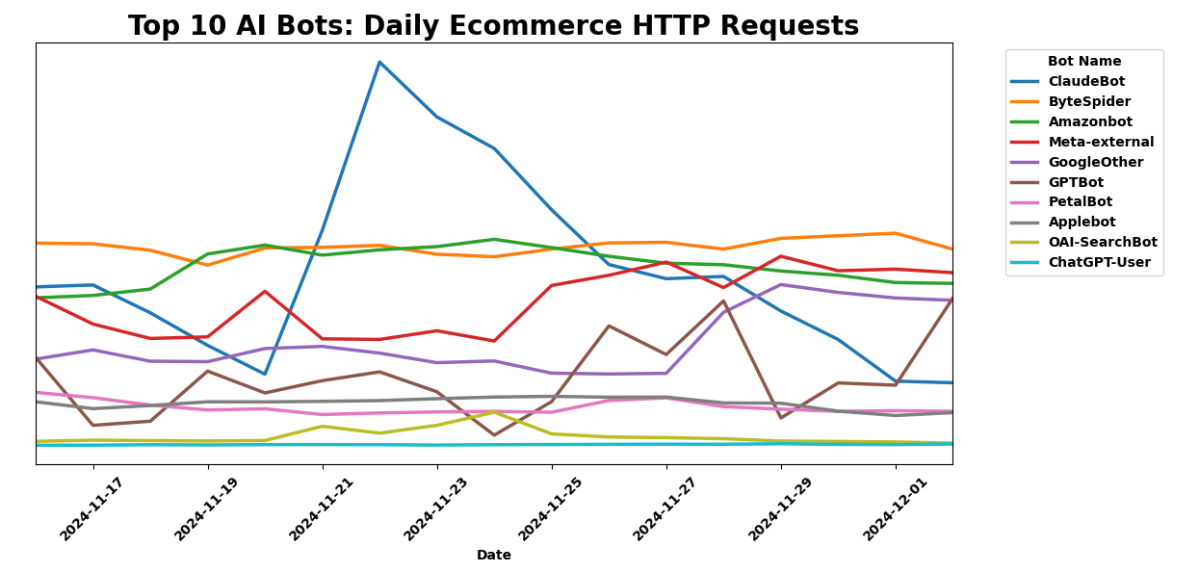
We looked at e-commerce sites specifically to find out if these bots were treating all content equally. While Meta-External and Amazonbot were still in the Top 3 of AI bots reaching e-commerce sites, Bytedance’s Bytespider crawled the most shopping sites.
In addition to scraping, crawling, and shopping, bots also targeted customer accounts on Black Friday. We saw 14.1 billion requests from bots to /login endpoints, accounting for 63% of that day’s login attempts. 
While this number seems high, intuitively it makes sense, given that humans don’t log in to accounts every day, but bots definitely try to crack accounts every day. Interestingly, while humans only accounted for 36% of traffic to login pages on Black Friday, this number was up 7-8% compared to the prior month. This suggests that more shoppers logged in to capitalize on deals and discounts on Black Friday than in preceding weeks. Human logins peaked at around 40% of all traffic to login sites on the Monday before Thanksgiving, and again on Cyber Monday.  
Separately, we also saw a 37% increase in leaked passwords used in login requests compared to the prior month. During Birthday Week, we shared how 65% of internet users are at risk of ATO due to re-use of leaked passwords. This surge, coinciding with heightened human and bot traffic, underscores a troubling pattern: both humans and bots continue to depend on common and compromised passwords, amplifying security risks.
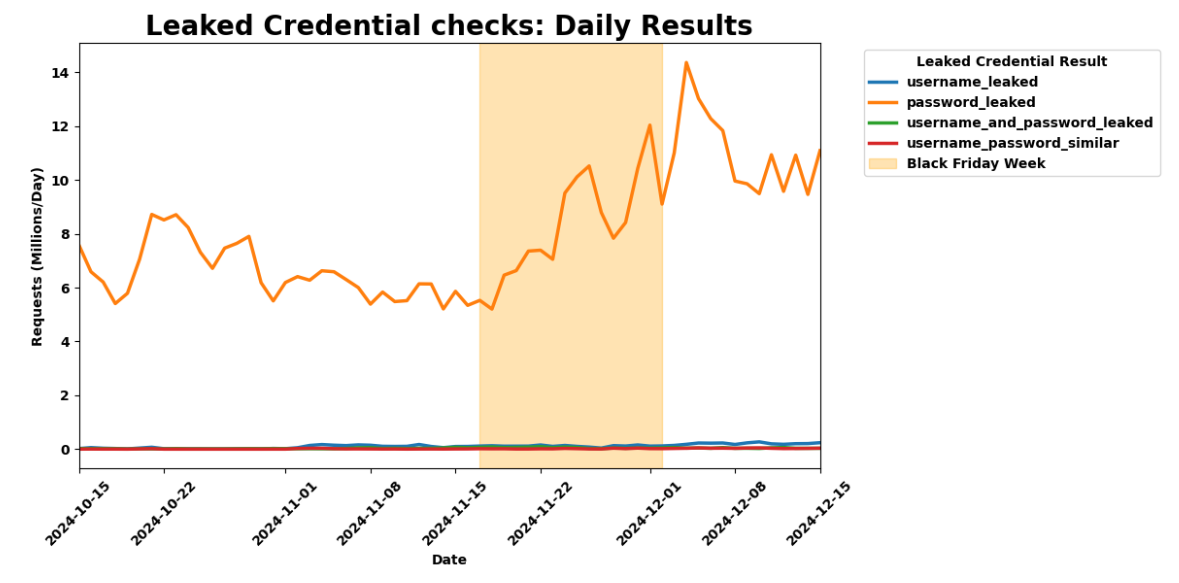
Proxy bots: Regardless of whether they’re crawling your content or hoarding your wares, 22% of bot traffic originated from residential proxy networks. This obfuscation makes these requests look like legitimate customers browsing from their homes rather than large cloud networks. The large pool of IP addresses and the diversity of networks poses a challenge to traditional bot defense mechanisms that rely on IP reputation and rate limiting. 
Moreover, the diversity of IP addresses enables the attackers to rotate through them indefinitely. This shrinks the window of opportunity for bot detection systems to effectively detect and stop the attacks. The use of residential proxies is a trend we have been tracking for months now and Black Friday traffic was within the range we’ve seen throughout this year.
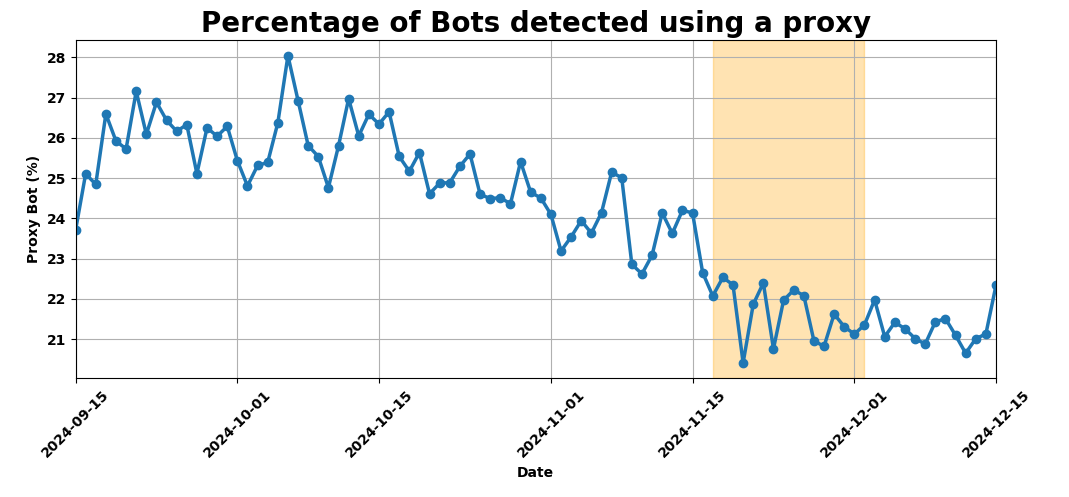
If you’re using Cloudflare’s Bot Management, your site is already protected from these bots since we update our bot score based on these types of network fingerprints. In May 2024, we introduced our latest model optimized for detecting residential proxies. Early results show promising declines in this type of activity, indicating that bot operators may be reducing their reliance on residential proxies. 
35% of all traffic on Black Friday was Grinch Bots. To keep Grinch Bots at bay, businesses need year-round bot protection and proactive strategies tailored to the unique challenges of holiday shopping.
Here are 4 yules (aka ‚Äúrules‚Ä? for the season:
(1) Block bots: 22% of bot traffic originated from residential proxy networks. Our bot management score automatically adjusts based on these network signals. Use our Bot Score in rules to challenge sensitive actions. 
(2) Monitor potential Account Takeover (ATO) attacks: Bots often test stolen credentials in the months leading up to Cyber Week to refine their strategies. Re-use of stolen credentials makes businesses even more vulnerable. Our account abuse detections help customers monitor login paths for leaked credentials and traffic anomalies.

Check out more examples of related rules you can create.
(3) Rate limit account and purchase paths: Apply rate-limiting best practices on critical application paths. These include limiting new account access/creation from previously seen IP addresses, and leveraging other network fingerprints, to help prevent promo code abuse and inventory hoarding, as well as identifying account takeover attempts through the application of detection IDs and leaked credential checks.
(4) Block AI bots abusing shopping features to maintain fair access for human users. If you’re using Cloudflare, you can quickly block all AI bots by enabling our automatic AI bot blocking feature.  

Over the next year, e-commerce sites should expect to see more humans shopping for longer periods. As sale periods lengthen (like they did in 2024) we expect more peaks in human activity on e-commerce sites across November and December. This is great for consumers and great for merchants.
More AI bots and agents will be integrated into e-commerce journeys in 2025. AI bots will not only be crawling sites for training data, but will also integrate into the shopping experience. AI bots did not exist in 2021, but now make up 1% of all bot traffic. This is only the tip of the iceberg and their growth will explode in the next year. We expect this to pose new risks as bots mimic and act on behalf of humans.
More sophisticated automation through network, device, and cookie cycling will also become a bigger threat. Bot operators will continue to employ advanced evasion tactics like rotating devices, IP addresses, and cookies to bypass detection.
Grinch Bots are evolving, and regulation may be slowing, but businesses don’t have to face them alone. We remain resolute in our mission to help build a better Internet ... and holiday shopping experience.
Even though the holiday season is closing out soon, bots are never on vacation. It’s never too late or too early to start protecting your customers and your business from grinches that work all year round.
Wishing you all happy holidays and a bot-free new year!
